
Wil je de volgende stap zetten in machine learning? Deze blog helpt je bij het opzetten van jouw eerste machine learning model, geschreven door de AI experts van DataNorth.
Basisprincipes van Machine Learning
Voordat we ons machine learning model opzetten, moeten we eerst de basisprincipes van machine learning begrijpen. In machine learning zijn er drie belangrijke typen machine learning: supervised learning, unsupervised learning en reinforcement learning.
- Supervised learning; gebruikt gelabelde datasets om algoritmen te trainen.
- Unsupervised learning; maakt gebruik van niet gelabelde datasets om algoritmen te trainen.
- Reinforcement learning; kan op zichzelf worden getraind door middel van vallen en opstaan en zal, afhankelijk van de resultaten, in de loop van de tijd verbeteren.
In deze blog hebben we het over supervised en unsupervised learning. Reinforcement learning gebruikt meer technische methoden en algoritmen, wat de volgende stap zou zijn in jouw machine learning reis.
Trainen van Machine Learning model
Installatie
Voordat je het model gaat trainen, moet je een aantal hulpmiddelen op jouw computer installeren om Python-code uit te voeren en jouw eerste machine learning model in te stellen.
- Python: Eerst moet je Python installeren. Het is de primaire programmeertaal voor machine learning en je kunt het downloaden van python.org.
- IDE/Editor: Je hebt ook een Integrated Development Environment (IDE) of een code-editor nodig om je Python-scripts te schrijven. Populaire keuzes zijn:
- Jupyter Notebook: Ideaal om te experimenteren met code in een interactieve, notebook omgeving. Je kunt het installeren via Anaconda of met de opdracht pip install notebook.
- VS Code: Een krachtige code-editor met geweldige ondersteuning voor Python. Installeer het hier en voeg de Python-extensie toe.
- Libraries: Om de machine learning modellen in deze blog uit te voeren, heb je de volgende Python bibliotheken nodig:
- NumPy: Voor het verwerken van arrays en wiskundige bewerkingen. Installeer het met pip install numpy.
- Scikit-learn: Een machine learningbibliotheek met algoritmen zoals lineaire regressie en KMeans. Installeer het met pip install scikit-learn.
Nadat je deze hulpmiddelen hebt geïnstalleerd, is de volgende stap het kiezen van het machine learning algoritme dat je wilt gebruiken.
Verzamelen van data
Wanneer je jouw eigen machine learning model start, is het eerste wat je moet doen; data verzamelen. Dit kan je eigen dataset zijn, of datasets van andere platforms zoals Kaggle. Kaggle is een platform dat datasets biedt die je kunt gebruiken om modellen te bouwen.
Bereid jouw gegevens voor
Wanneer je je dataset hebt, moet je beslissen of de bruikbaarheid hoog genoeg is om te gebruiken voor je machine learning model. Met bruikbaarheid bedoelen we dat de dataset voldoende gegevens heeft om mee te werken. Wanneer er gegevens ontbreken, onjuiste gegevens of outliers zijn, moeten we eerst de dataset opschonen. Wanneer gegevens moeten worden opgeschoond, kun je de onderstaande stappen volgen om de gegevens voor te bereiden voordat je deze gebruikt om je model te trainen.
Belangrijkste stappen voor data voorbereiding
- Gegevens opschonen; duplicaten verwijderen om onbevooroordeelde resultaten te voorkomen
- Feature engineering; nieuwe features maken van bestaande data en categorische variabelen coderen in numerieke formaten.
- Normalisatie en schaling; numerieke features normaliseren om een vergelijkbare schaal te garanderen met behulp van technieken zoals min-max schaling of z-score normalisatie.
- Outlier management; outliers identificeren en bepalen hoe ze behandeld moeten worden op basis van hun impact op jouw model.
- Data splitsen; je dataset verdelen in trainings- en testsets.
- Feature selectie; relevante features selecteren om de modelprestaties te verbeteren en overfitting te verminderen.
- Data validatie; controles uitvoeren om te garanderen dat het opschoningsproces geen biases of fouten heeft geïntroduceerd.
Waar de dataset moet worden geplaatst
Organiseer je bestanden door je dataset op te slaan in een map op jouw computer, idealiter in een directory waar al jouw projectbestanden worden opgeslagen. Om jouw dataset in Python te laden, kunt u bibliotheken zoals Pandas gebruiken om de dataset in jouw script te laden.

Een model kiezen
Nu je dataset klaar is, is de volgende stap het kiezen van een model. Dit hangt af van verschillende factoren, waaronder het type probleem dat je oplost (classificatie, regressie, clustering, enz.).
Laten we het opsplitsen, aan het begin van deze blog hadden we het over de typen machine learning; supervised learning, unsupervised learning en reinforcement learning. Laten we de typen machine learning modellen matchen met methoden en algoritmen om het gemakkelijker te maken om je model te kiezen.
Supervised learning benaderingen
Supervised learning houdt in dat een model wordt getraind met behulp van gelabelde data en kan worden onderverdeeld in twee hoofdbenaderingen: classificatie en regressie. Classificatie richt zich op het toewijzen van datapunten aan vooraf gedefinieerde labels of klassen, zoals het identificeren of een e-mail spam is of niet. Daarentegen wordt regressie gebruikt om continue numerieke waarden te voorspellen, zoals het voorspellen van huizenprijzen of trends op de aandelenmarkt.
| Belangrijkste verschillen | ||
| Functie | Classificatie | Regressie |
| Uitvoer | Discrete categorieën (e.g., 0, 1, “A”, “B”) | Continue waarden (e.g., 3.5, 98.7) |
| Doel | Classificeren in categorieën | Voorspel numerieke output |
| Use case | Fraudedetectie, ziektediagnose | Prijsvoorspelling, voorraadprognose |
| Variabele | Categorisch | Continue |
Classificatie
Dit is een machine learning methode die probeert het juiste label van een gegeven invoerdata te voorspellen. Als voorbeeld nemen we twee classificatiealgoritmen; Naive Bayes en Super Vector Machine. Deze algoritmen bouwen een model van de trainingsdataset voordat ze een voorspelling doen over toekomstige datasets. Algoritmen die je kunt gebruiken bij het gebruik van deze methode;
- Naive bayes
- Super Vector Machine
Regressie
Dit is een machine learning methode die wordt gebruikt om de relatie tussen een afhankelijke variabele (doelvariabele) en een onafhankelijke variabele (voorspellende variabele) te analyseren. Het doel is om de krachtigste functie te bepalen die de verbinding tussen deze twee karakteriseert. Algoritmen die voor deze methode moeten worden gebruikt;
- Decision tree
- Logistic regression
- Linear regression
Unsupervised learning
Unsupervised learning is een type machine learning dat werkt met ongelabelde data en verborgen patronen of structuren daarin ontdekt. Twee primaire benaderingen zijn clustering en dimensionaliteitsreductie. Clustering is gericht op het groeperen van vergelijkbare datapunten in clusters op basis van gedeelde patronen of kenmerken, zoals het segmenteren van klanten op basis van aankoopgedrag. Dimensionaliteitsreductie vereenvoudigt datasets door het aantal kenmerken te verminderen en tegelijkertijd zoveel mogelijk waardevolle informatie te behouden, vaak gebruikt voor het visualiseren van hoogdimensionale data of het verbeteren van de modelefficiëntie.
| Belangrijkste verschillen | ||
| Functie | Clustering | Dimensionality reduction |
| Uitvoer | Clusterlabels voor datapunten (e.g., “Cluster 1”, “Cluster 2” | Een dataset met minder dimensies, meestal in numerieke vorm |
| Doel | Groeperen van vergelijkbare datapunten in clusters | Vermindering van de complexiteit van gegevens, terwijl belangrijke informatie behouden blijft |
| Use case | Klanten segmentatie, patroonherkenning, anomaliedetectie | Datavisualisatie, verbetering van modelprestaties |
| Variable | Gebruikt originele variabelen om clusters te vormen | Transformeert variabelen in nieuwe combinaties of een lager dimensionale ruimte |
Clustering
Dit is een machine learning methode die zowel categorische als numerieke functies gebruikt om ongelabelde data te groeperen op basis van hun overeenkomsten met elkaar. Algoritmen die je kunt gebruiken bij het gebruik van deze methode;
- K-means
- Mean shift
Dimensionality reduction
Dit is een machine learning methode voor het weergeven van een gegeven dataset met een lager aantal kenmerken. Het verwijdert irrelevante gegevens om een model te maken met een lager aantal variabelen. Algoritmen om te gebruiken bij het gebruik van deze methode;
- Principal component analysis
- Feature selection
- Linear discriminant analysis
Het model trainen
In dit hoofdstuk doorlopen we alle stappen om je eigen machine learning model te trainen. Van wat we eerder hebben besproken, kun je de twee machine learning methoden gebruiken: supervised en unsupervised learning. Nu richten we ons op de technische aspecten van het opzetten van het machine learning model.
Supervised learning
Het machine learning algoritme wordt getraind op een gelabelde dataset. Dit betekent dat het algoritme voor elk voorbeeld in de trainingsdataset weet wat de juiste uitvoer is. Het algoritme gebruikt die kennis om te proberen te generaliseren naar nieuwe voorbeelden die het nog nooit eerder heeft gezien. Met behulp van gelabelde invoer en uitvoer kan het model zijn nauwkeurigheid meten en in de loop van de tijd leren.
Voor dit voorbeeld gebruiken we lineaire regressie, laten we samen een lineair regressiemodel trainen. Laten we dit voorbeeld van sklearn nemen om de stappen voor het opzetten van een lineaire regressie door te nemen.

Stap 1: Open je IDE of code editor
Om te beginnen open je je IDE of code-editor, zoals Jupyter Notebook of VS Code.
Stap 2: Importeren van je Libraries
Importeren van een library (NumPy) voor het werken met getallen en arrays (getaltabellen).
import numpy as npVervolgens wordt er een hulpmiddel genaamd Lineaire Regressie ingezet om relaties tussen getallen te vinden.
from sklearn.linear_model import LinearRegressionStap 3: Data punten vaststellen (X and y)
Wat is X?
x is een tabel waarin elke rij een set invoernummers vertegenwoordigt. Elke invoer heeft twee nummers (kolommen). Bijvoorbeeld, de eerste rij [1, 1] betekent dat de eerste invoer 1 is, en de tweede invoer is ook 1.
Wat is y?
y is een set uitvoergetallen die worden berekend met behulp van een specifieke regel. Zie het als de “antwoorden” die overeenkomen met elke rij in X.
Volg voor elke rij in X deze regel: neem het eerste getal en vermenigvuldig het met 1, neem vervolgens het tweede getal en vermenigvuldig het met 2. Tel deze twee resultaten bij elkaar op en tel er ten slotte 3 bij op om het totaal te krijgen.
Stap 4: Trainen van het Model
reg = LinearRegression().fit(X, y): Traint het model om de relatie tussen X en y te leren met behulp van lineaire regressie.
Stap 5: Controleren
reg.score(X, y): Controleert hoe goed het model de relatie heeft geleerd. Een score van 1,0 betekent dat het model de relatie perfect heeft geleerd.
Stap 6: Vinden van relaties
reg.coef_: Geeft de coëfficiënten (gewichten) weer die het model voor elke kolom in X heeft geleerd. Het resultaat is [1.,2.], de eerste kolom wordt vermenigvuldigd met 1 en de tweede met 2.
reg.intercept_: Geeft de constante (startpunt) weer die het model heeft geleerd. In dit geval is het resultaat 3.0.
Stap 7: Voorspellingen maken
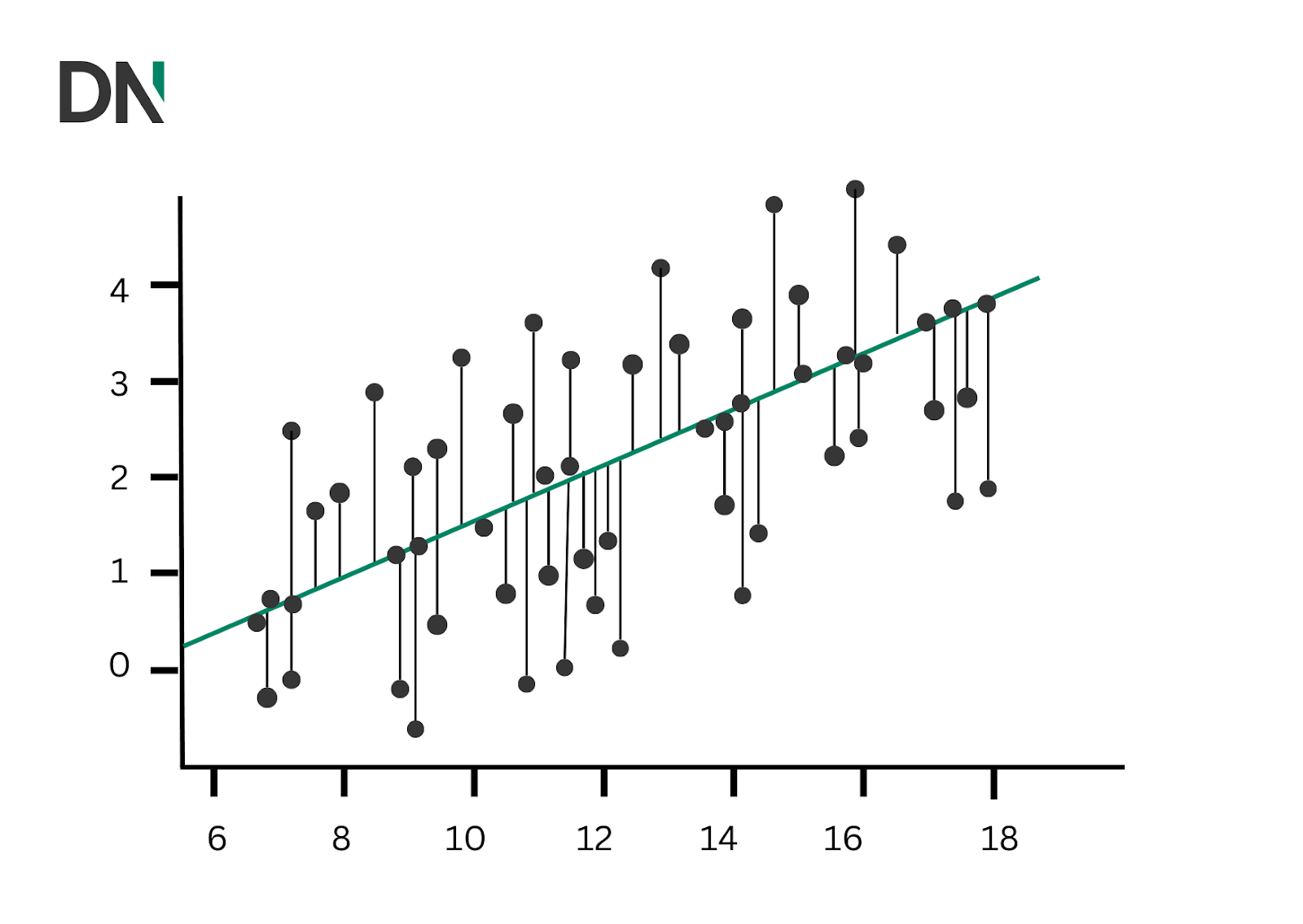
reg.predict(np.array([[3, 5]])): Voorspelt de uitvoer voor nieuwe invoer [3, 5]. De gebruikte formule; (1×3) + (2×5) + 3 = 16. Wat resulteert in [16]. Hieronder zie je een voorbeeld van hoe een lineaire regressie eruit zou zien. Zoals je kunt zien is het een rechte lijn die omhoog gaat, waarbij elk punt een relatie tussen twee dingen vertegenwoordigt. Het doel is om de rechte lijn te tekenen die het beste tussen die punten past. De lijn helpt je vervolgens de waarde van de gegevens die je wilt verzamelen te voorspellen.
Unsupervised learning
Dit machine learning algoritme is getraind op een ongelabelde dataset. Daarom moet het algoritme verborgen patronen in data ontdekken zonder dat er menselijke input nodig is.
Voor dit voorbeeld gebruiken we k-means, laten we samen een k-means model trainen. Laten we weer naar sklearn gaan voor een voorbeeld en de stappen doorlopen voor het opzetten van een k-means model.

Stap 1: Open je IDE of code editor
Om te beginnen open je je IDE of code-editor, zoals Jupyter Notebook of VS Code.
Stap 2 : Importeren van Libraries
Importeer een library (NumPy) voor het werken met getallen en arrays (getaltabellen).
import numpy as npVervolgens wordt er een hulpmiddel genaamd Lineaire Regressie ingezet om relaties tussen getallen te vinden.
from sklearn.linear_model import KMeansfrom sklearn.cluster import KMeans: Brengt een tool genaamd KMeans, die wordt gebruikt voor het groeperen van datapunten in clusters op basis van hun overeenkomsten. KMeans helpt patronen te identificeren door vergelijkbare data te groeperen.
Stap 3: Data punt vaststellen (X)
Eerst maken we wat data die we willen groeperen. Je X waarden zijn de data die we gaan analyseren en het vertegenwoordigt de punten die we willen clusteren (groeperen) op basis van hun overeenkomsten. We hebben y niet nodig in KMeans omdat het geen gelabelde data gebruikt (het is unsupervised learning). Voor KMeans richten we ons alleen op de X data.
Stap 4: Controleren
Nu trainen we het model. KMeans; dit betekent dat we het algoritme vragen om naar de data te kijken en te bepalen in hoeveel groepen (clusters) het de data moet verdelen. Je kunt KMeans bijvoorbeeld vertellen dat je 2 clusters (groepen) wilt, en het zal twee sets punten vinden die dicht bij elkaar liggen.
Stap 5: Vinden van relaties
Zodra het model is getraind, kunnen we controleren hoe goed het de data heeft gegroepeerd door te kijken welke punten tot welke groep behoren. KMeans geeft elk punt een “label”; kmeans.labels. Het laat zien tot welke groep het behoort. KMeans zou bijvoorbeeld kunnen zeggen dat de eerste drie punten tot één groep behoren en de laatste drie tot een andere.
Stap 6: Voorspellingen maken
Ten slotte kun je het model vragen om te voorspellen tot welke groep een nieuw punt zal behoren. De KMeans clustering grafiek toont datapunten gegroepeerd in clusters, elk weergegeven door een andere kleur. Het algoritme verdeelt de punten op basis van hun overeenkomsten, wat de gemiddelde positie is van alle punten in die groep. Elk punt wordt toegewezen aan een cluster en de clusters helpen patronen in de data te identificeren op basis van hoe dicht de punten bij elkaar liggen.

Conclusie
Ter afsluiting van deze blog hebben we besproken wat machine learning is en hebben we je voorbeelden gegeven van hoe je je eerste machine learning model kunt opzetten. Of je nu supervised learning gebruikt zoals lineaire regressie voor gelabelde data of unsupervised learning zoals kmeans clustering voor ongelabelde data. Het proces voor het opzetten van een machine learning model omvat het begrijpen van het probleem, het voorbereiden van de data en het kiezen van het juiste model. Door deze stappen te volgen, kun je beginnen met het bouwen van je eigen machine learning model. Over het algemeen is het belangrijk om te experimenteren met verschillende modellen en te kijken welke het beste werkt voor jouw datatype.
Als je klaar bent om de volgende stap te zetten in je machine learning reis, maar meer expertise wilt, staan wij van DataNorth voor je klaar. Onze AI engineers hebben hun bachelors en masters in dit vakgebied en zijn er om je te adviseren in je machine learning proces. Aarzel niet om contact met ons op te nemen.



