

Op 30 november kondigde DeepSeek-AI de release aan van DeepSeek-V3.2 en DeepSeek-V3.2-Speciale, waarmee reasoning-first modellen werden geïntroduceerd die zijn ontworpen voor agentic applicaties. DeepSeek-V3.2 dient als de officiële opvolger van het experimentele V3.2-Exp model en behaalt prestaties op GPT-5-niveau, terwijl V3.2-Speciale rivaliseert met Gemini-3.0-Pro op het gebied van redeneercapaciteiten.
Beschikbaarheid en toegang tot het model
DeepSeek-V3.2 is beschikbaar via meerdere kanalen, waaronder de DeepSeek-webinterface, mobiele app en API. Het model behoudt dezelfde gebruikspatronen als de voorgaande V3.2-Exp variant.
DeepSeek-V3.2-Speciale is momenteel exclusief beschikbaar via API via een tijdelijk endpoint, toegankelijk tot 15 december 2025. Deze variant hanteert dezelfde prijsstructuur als V3.2, maar ondersteunt geen tool calls tijdens de evaluatieperiode. De Speciale-variant is geoptimaliseerd voor complexe redeneertaken (reasoning tasks), maar vereist een hoger tokenverbruik in vergelijking met het standaard V3.2-model.
Beide modellen zijn vrijgegeven als open-source onder de MIT-licentie, waarbij de model weights beschikbaar zijn op Hugging Face.
Technische architectuur
DeepSeek-V3.2 introduceert DeepSeek Sparse Attention (DSA), wat de computationele complexiteit vermindert van $O(L^2)$ naar $O(kL)$, waarbij $L$ de sequentielengte vertegenwoordigt en $k$ de geselecteerde tokens. Deze architecturele innovatie maakt een reductie van ongeveer 50% in computationele kosten mogelijk voor scenario’s met een lange context (long-context), terwijl de prestaties van het model behouden blijven. Beide modellen ondersteunen context windows tot 128.000 tokens.
Het model maakt gebruik van een Mixture-of-Experts architectuur die per token slechts een subset van parameters activeert. Dit maakt efficiënte inference mogelijk tegen API-prijzen die aanzienlijk lager liggen dan bij propriëtaire alternatieven.
Benchmark-prestaties
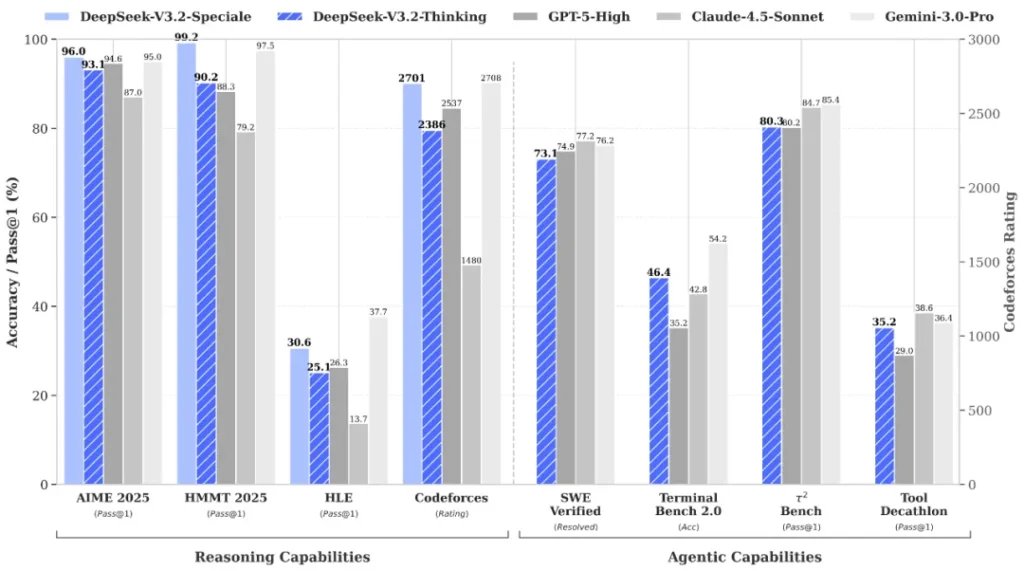
DeepSeek-V3.2 behaalde 93,1% nauwkeurigheid op AIME 2025 wiskundeproblemen en bereikte een Codeforces-rating van 2386. Het model scoorde 85,0% op MMLU-Pro, 82,4% op GPQA Diamond en 83,3% op LiveCodeBench.
DeepSeek-V3.2-Speciale demonstreerde 96,0% nauwkeurigheid op AIME 2025 en behaalde een Codeforces-rating van 2701. De Speciale-variant behaalde gouden medaille-prestaties in vier grote competities: de Internationale Wiskunde Olympiade 2025 (IMO), de Chinese Wiskunde Olympiade (CMO), de ICPC World Finals en de Internationale Informatica Olympiade (IOI).
‘Thinking’ in tool-use integratie
DeepSeek-V3.2 vertegenwoordigt het eerste model van DeepSeek dat redeneerprocessen direct integreert in scenario’s voor tool-calling. Het model ondersteunt zowel thinking als non-thinking modi voor het gebruik van tools.
De gehanteerde trainingsmethodologie maakte gebruik van een grootschalige pijplijn voor synthese van agentic tasks, die meer dan 1.800 verschillende omgevingen en 85.000 complexe instructies dekte. Deze uitgebreide synthetische data zorgde voor aanzienlijke verbeteringen in generalisatie en het opvolgen van instructies (instruction-following) binnen complexe interactieve omgevingen.
Op agent-gerichte benchmarks behaalde DeepSeek-V3.2 scores van 73,1% op SWE-Verified, 70,2% op SWE-Multilingual, 46,4% op Terminal Bench 2.0 en 38,0% op MCP-Mark.
Prijzen en implementatie
De API-prijzen worden tijdens de evaluatieperiode gehandhaafd op $0,028 per miljoen input-tokens voor zowel V3.2 als V3.2-Speciale. De open-source release stelt organisaties in staat om self-hosted deployments te implementeren met volledige datacontrole en aanpassingsmogelijkheden.
Het technische rapport en de implementatiedetails zijn beschikbaar via de officiële DeepSeek Hugging Face-repository.
Voor meer informatie kun je de officiële aankondiging van DeepSeek V3.2 bezoeken.



