

On November 30th, DeepSeek-AI announced the release of DeepSeek-V3.2 and DeepSeek-V3.2-Speciale, introducing reasoning-first models designed for agentic applications. DeepSeek-V3.2 serves as the official successor to the experimental V3.2-Exp model and achieves GPT-5-level performance, while V3.2-Speciale rivals Gemini-3.0-Pro in reasoning capabilities.
Model availability and access
DeepSeek-V3.2 is available through multiple channels including the DeepSeek web interface, mobile app, and API. The model maintains the same usage patterns as the previous V3.2-Exp variant.
DeepSeek-V3.2-Speciale is currently available exclusively through API via a temporary endpoint, accessible until December 15, 2025. This variant uses the same pricing structure as V3.2 but does not support tool calls during the evaluation period. The Speciale variant is optimized for complex reasoning tasks but requires higher token usage compared to the standard V3.2 model.
Both models are released as open-source under MIT license, with model weights available on Hugging Face.
Technical architecture
DeepSeek-V3.2 introduces DeepSeek Sparse Attention (DSA), which reduces computational complexity from O(L²) to O(kL), where L represents sequence length and k denotes selected tokens. This architectural innovation enables approximately 50% reduction in computational costs for long-context scenarios while maintaining model performance. Both models support context windows up to 128,000 tokens.
The model utilizes a Mixture-of-Experts architecture that activates only a subset of parameters per token, enabling efficient inference at API pricing significantly lower than proprietary alternatives.
Benchmark performance
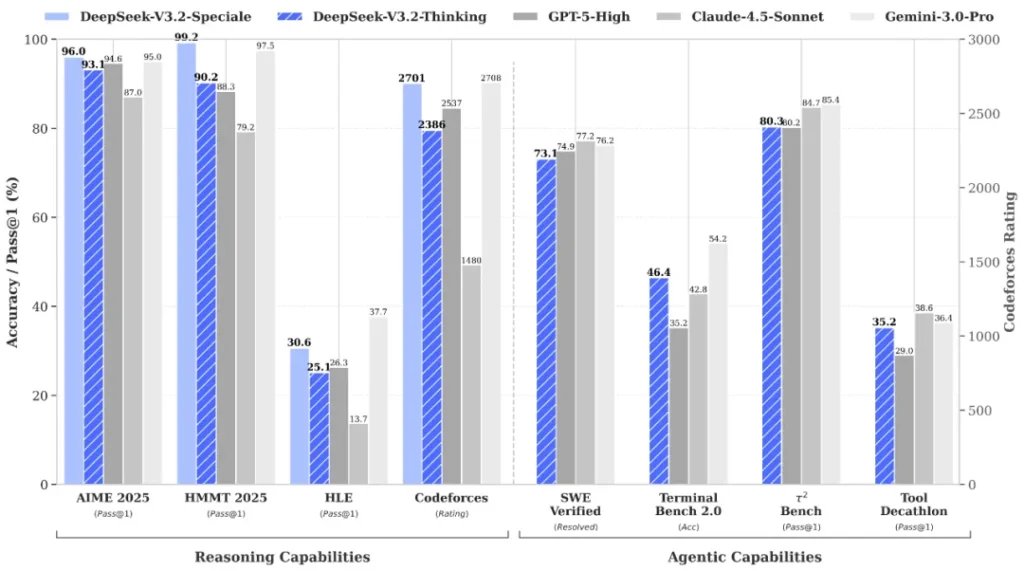
DeepSeek-V3.2 achieved 93.1% accuracy on AIME 2025 mathematics problems and attained a Codeforces rating of 2386. The model scored 85.0% on MMLU-Pro, 82.4% on GPQA Diamond, and 83.3% on LiveCodeBench.
DeepSeek-V3.2-Speciale demonstrated 96.0% accuracy on AIME 2025 and achieved a Codeforces rating of 2701. The Speciale variant attained gold-medal performance in four major competitions: the 2025 International Mathematical Olympiad (IMO), Chinese Mathematical Olympiad (CMO), ICPC World Finals, and International Olympiad in Informatics (IOI).
Thinking in tool-use integration
DeepSeek-V3.2 represents the first model from DeepSeek to integrate reasoning processes directly into tool-calling scenarios. The model supports both thinking and non-thinking modes for tool use.
The training methodology employed a large-scale agentic task synthesis pipeline covering over 1,800 distinct environments and 85,000 complex instructions. This extensive synthetic data enabled substantial improvements in generalization and instruction-following capabilities within complex interactive environments.
On agent-focused benchmarks, DeepSeek-V3.2 achieved 73.1% on SWE-Verified, 70.2% on SWE-Multilingual, 46.4% on Terminal Bench 2.0, and 38.0% on MCP-Mark.
Pricing and implementation
API pricing is maintained at $0.028 per million input tokens for both V3.2 and V3.2-Speciale during the evaluation period. The open-source release enables organizations to implement self-hosted deployments with complete data control and customization capabilities.
The technical report and implementation details are available through the official DeepSeek Hugging Face repository.
For more information please visit the official DeepSeek V3.2 announcement



